基于 Redis ( Tair ) 的 Hash 实现滑动窗口
大家在做限流(Rate Limiting)的时候,肯定接触过滑动窗口这个概念。 我前段时间要做一个风控系统,实现过程中有一个比较关键的部分,也是滑动窗口。
与限流的不同的是,限流往往大家只是从固定窗口→滑动窗口→漏桶→令牌桶有个概念上的了解就行了,最终往往只会使用令牌桶算法。而风控系统里的实时统计则不同,必须用滑动窗口来做。
如果是单机滑动窗口,其实做起来挺容易的。Sentinel 内置的高性能滑动窗口数据结构 LeapArray 就可以直接拿来使用。
但是如果是分布式的,则实现起来有些费劲。
一般可选的方案如下:
- 基于 Redis 的 SortedSet
- 基于 HBase 的列族
- 基于第四代大数据计算引擎 Flink
其中的 HBase,虽说我之前有过接触,但公司目前却没有 HBase 的集群,还需要重新搭建。 至于 Flink,更是不太了解并且没有相关环境了。 其实还可以基于 Key Based Routing 和本地缓存来做分布式滑动窗口,但复杂度较高,且维护成本高。
这里我比较熟悉的就是 Redis 了,用 SortedSet 实现滑动窗口也比较容易,网上一搜也是一大片类似的教程,这里大概说一下。
首先 SortedSet 存储结构如下: * key:功能 id * value:无意义的 uniqId(比如 UUID) * score:时间戳
然后结合 ZADD、EXPIRE、ZCOUNT
和 ZREMRANGESCORE 四个命令就可以实现, 同时可用 Pipeline
来尽可能提升性能。
伪代码如下:
1 | |
但是该方法,有两个比较突出的问题:
- 这是一个重操作,将引发高 QPS 下 Redis 的性能瓶颈
- 消耗的资源较多(要记录时间窗口内所有的行为记录,类似于记日志一样)
对于第一个问题,我们可以用异步的方式来优化,比如将计数、删除过期数据和新增记录分为三部分去进行异步处理。
但对于第二个问题,我们能做的就特别有限了。
Redis 目前已经快成行业内的标配了,其中一个优势就是有多种简洁实用的数据结构。
那能不能将 SortedSet 换一种数据结构呢?
这时候我们再回到滑动窗口本身。
其实就是设定的单位时间就是一个窗口,窗口可以分割多个更小的时间单元,随着时间的推移,窗口会向右移动。
比如在限流策略里,一个接口 1 分钟内限制调用 1000 次,1 分钟就可以理解为一个窗口,可以把 1 分钟分割为 10 个单元格,每个单元格就是 6 秒。
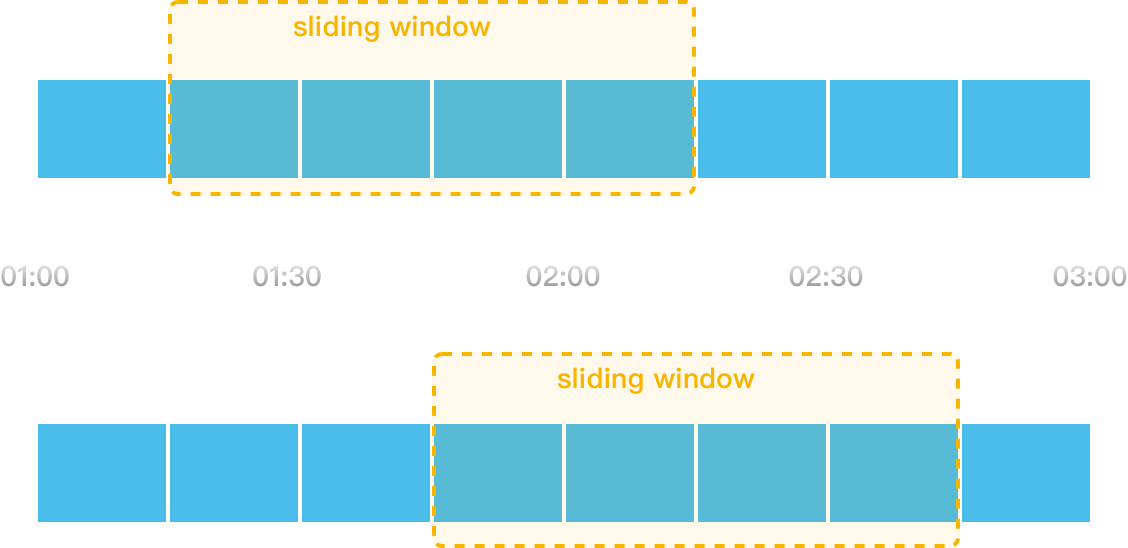
除了 SortedSet 之外,其实 Redis 里的 Hash 也能实现类似的结构: * key:功能 id + 时间窗标识 * field:时间维度(比如秒级时间戳,下边会详说) * value:计数器
然后结合
HGETALL/HVALS、HINCRBY、HDEL、EXPIRE
也可实现滑动窗口的效果。伪代码如下:
1 | |
这样就解决了 SortedSet “记日志”耗资源的问题了。
但是 SortedSet 的问题 1 依旧存在:这仍是一个重操作。优化思路如下:
- 首先是使用 Pipeline,并将 HDEL 优化为批量的方式
- 将新增记录、计数、删除过期数据分为三部分去进行异步处理
常规的优化到这里基本就达到瓶颈了。但是这肯定还达不到我们的要求,我们要进一步压榨性能。
首先是可以缩短 field 的长度,在 HGETALL/HVALS
的时候减少数据传输。
之前 field 是时间戳,目前的秒级时间戳在 10 位,如果是
MMddHHmmss 格式的话也是 10 位。
我们可以先从秒级时间戳“抹去”年份,能省 3 位,得 7 位。
再看一下之前说的“1 分钟分割为 10 个单元格,每个单元格就是 6
秒”,可以发现我们不必在一个 1 分钟的时间窗里存 60 个每秒的分片,而是存
10 个 6 秒的分片,这样既可减少 field 的数量,也可缩短 filed 的位数,在
HGETALL/HVALS 的时候最多可以减少约 85%
的数据传输。代码也比较简单:
1 | |
删除过期数据这一块,我猜大家肯定都会想,要是能单独在 field
上加过期时间,该多好啊,就不用 HDEL 了。
原生的 Redis 是不支持在 field 上加过期的,而我司有用阿里云的企业版的 Redis(其实就是 Tair),Tair 里边有个更高级的 Hash 结构——TairHash,可以支持在 field 上单独加过期时间。
如果大家能用到 Tair,可以如下实现:
1 | |
注意这里不用对 redis 的 key 进行 expire 设置过期时间,在 field 全部过期后,这个 key 也就自然不存在了。
如果是非要对 key
设置过期时间来兜底的话,注意时间要设置为时间窗口时间*2。
思考一下:这里为什么要
*2呢?
使用 TairHash 时有几个点需要注意一下: * > 警告
TairHash与Redis中的原生Hash是两种不同的数据,相关命令不可混用。 * 在阿里云的官方文档里,EXHVALS
和 EXHGETALL 的时间复杂度都是 O(1)(原生 Redis
Hash 对应的命令都为 O(N))  *
*
EXHVALS 和 EXHGETALL 均是获取 key 指定的
TairHash 中所有的 value(或 +field)。这俩命令都是仅过滤掉已经过期的
field,不会执行真正的删除操作。即不会触发对 field 的被动淘汰。
好了,至此一个基于 Tair 实现的分布式滑动窗口就可以用了。
如果你有更好的方案,或者有问题,都可以留言提出~
源码在这里:https://github.com/zhaoyibo/sea-of-stars/tree/master/time-window
参考: * 已经触碰到Redis的性能边缘? 看看久经考验的Redis企业版(Tair)吧 * TairHash命令 * TairHash内存消耗与淘汰策略最佳实践 * tairjedis-sdk